In today’s competitive landscape, deploying #AI is no longer sufficient to secure a market advantage. The true differentiator lies in accessing and leveraging diverse, extensive, and high-quality data that can significantly enhance AI performance compared to competitors. However, data privacy concerns often hinder the utilization of unique and relevant datasets necessary for robust AI training. Collaborative Machine Learning emerges as a transformative solution to this challenge by enabling AI model training across multiple, decentralized data sources while preserving data privacy.
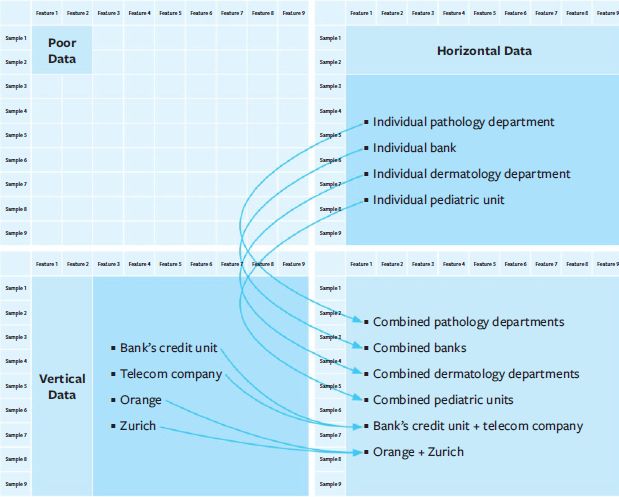
To effectively harness collaborative learning, organizations must first understand the structure and quality of their own data. Data can be categorized as poor, vertical, horizontal, or rich, each requiring different collaborative learning strategies. Rich data, characterized by a large number of samples and features, positions companies to maximize AI potential independently, while collaborative learning offers opportunities to monetize this data by contributing to external AI training initiatives. Conversely, organizations with vertical or horizontal data must seek appropriate partners—across or within industries, respectively—to complement their datasets and transform their AI capabilities.
By understanding and strategically leveraging their unique data landscapes, organizations can effectively employ collaborative machine learning to train powerful AI models together, enhance performance, and achieve sustainable competitive advantage all while safeguarding data privacy and integrity.
#ArtificialIntelligence #DataDriven #DataStrategy #MachineLearning
